Web Scraping with Cypress with a Practical Example
Everyone has a dream. Yours is to use Cypress for web scraping. For the grandparents of one of my close friends, however, it was to win the lottery. They were obsessed and determined to win, no matter how long it takes. That’s why they tried to crack the secret and worked day and night to formulate the perfect winning numbers over the years. And they eventually managed to do so — at least they thought. They are playing with it since 1973 — for more than 40 years consistently, in hopes of winning the jackpot, still waiting for the big breakthrough.
And this is what we are going to use as an example to collect data with Cypress using web scraping — collect the winning numbers of all time and check the odds. So I went to the official website of the Hungarian national lottery and there they were: the all-time winning numbers.
Of course, it would be super tedious to collect them manually and there isn’t an API we can interact with, so we can turn to web scraping:
A way to extract data from websites without an API.
The Concept
First, we will see how we can collect information from an HTML page using Cypress. The page in questions looks like the following:
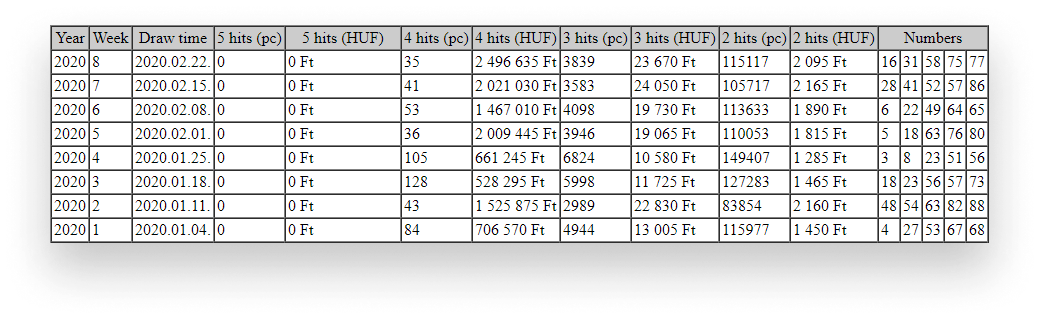
The rules of the game are: pick 5 different numbers between 1 and 90. Luckily for us, the data is at least preformatted in a table. I’ve renamed the columns so it makes sense to you what we’re looking at. The list of results goes all the way down to 1957, counting up to 3287 rows in total. We want to collect the numbers from the “Numbers” column in each row.
Then we want to create an object from it and lastly save it to a JSON file for later reuse. In the end, we can check if one of the 5 numbers has been drawn multiple times. We can also check what numbers have been picked the most.
So let’s begin by grabbing everything we can and generating structured data from it.
Grabbing the Data with DOM Scraping
First, we want to set up Cypress by running npm i cypress --save-dev. I’ve also added the start script to my package.json file so we can run it without having to type in the full node_modules path:
{
"name": "cypressio",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"cypress": "node_modules\\.bin\\cypress open"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"cypress": "10.0.2"
}
}If you would like to learn more about Cypress itself, I have a tutorial that goes more in-depth. you can reach it at the provided link above.
After we are done with that, let’s create a new test file where we are going to collect the necessary information:
describe('Collecting Data', () => {
before(() => {
cy.visit('https://bet.szerencsejatek.hu/cmsfiles/otos.html');
});
it('creating data object', () => {
const results = [];
cy.get('tr').each(($tr, index) => {
if (index !== 0) {
const rowElement = $tr.get(0);
const cells = rowElement.cells;
results.push({
year: cells[0].innerText,
week: cells[1].innerText,
drawDate: cells[2].innerText,
numbers: [
parseInt(cells[11].innerText, 10),
parseInt(cells[12].innerText, 10),
parseInt(cells[13].innerText, 10),
parseInt(cells[14].innerText, 10),
parseInt(cells[15].innerText, 10)
]
});
}
}).then(() => {
console.log(results);
});
});
});Before everything, we want to visit the page from which we want to gather the data.
I’ve created a results array which will hold each row in an object with the info we need. Then we loop through each table row. We want to skip the very first row as it’s only containing th elements, that’s why we need the if statement at the very beginning. After that, I’ve created two variables as we’re going to access the element multiple times:
$tris a wrapped JQuery object so we want to get the underlying DOM attributes withget(0).rowElement.cellsis anHTMLCollectionholding data for each column.
Notice that since there are no classes we can select, we need to count the child elements of each row. After this, we should end up with the following structured data:


Saving the Scraped Data to JSON
We can easily save this data for later reuse by changing the console.log in the then clause to the following line:
}).then(() => {
cy.writeFile('results.json', results);
});This will create a file in the project root directory, next to cypress.json. Now that we have everything available, we can move on to calculating our odds and cracking the secrets to formulating the perfect set of winning numbers.
Web scraping is about traversing the DOM and grabbing the necessary information from it.
Calculating The Odds
First, let’s see if there’s any recurrence of the drawn numbers. Let’s first create a new array out of only the winning numbers and then we can create a function for counting unique values.
For this, I’ve opened the generated JSON file in Chrome and I’m using the console to get the results:

I’m using the JSON Viewer Chrome extension so I have access to the JSON object via window.json:
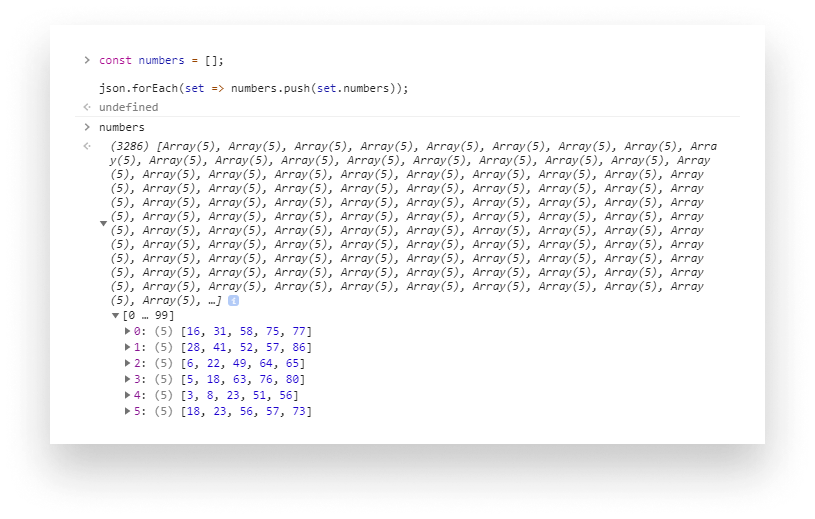
First, we loop through the results and create a new array for each set of winning numbers. Then we can create a function for counting occurrences:
const counts = {};
numbers.forEach(numberSet => counts[numberSet] = counts[numberSet] ? counts[numberSet] + 1 : 1);For each set of picks, we check if it already exists in the counts object. If it is, we increase its value by one, otherwise, we add it to the object. Running this in the console we get the following list of numbers and the number of times they have been drawn.
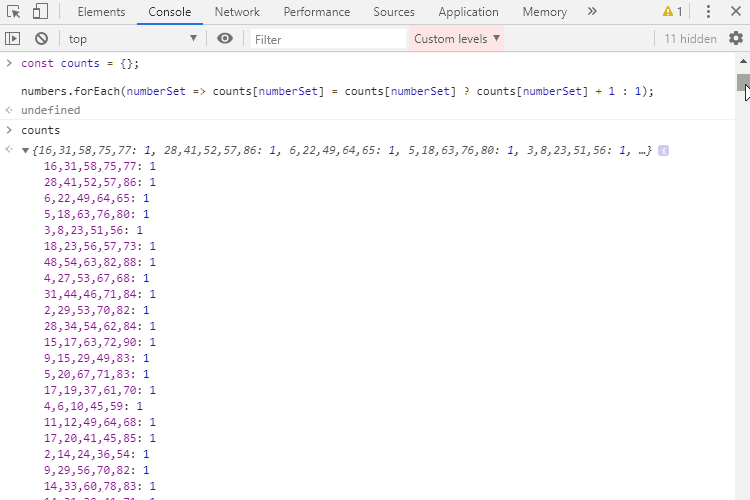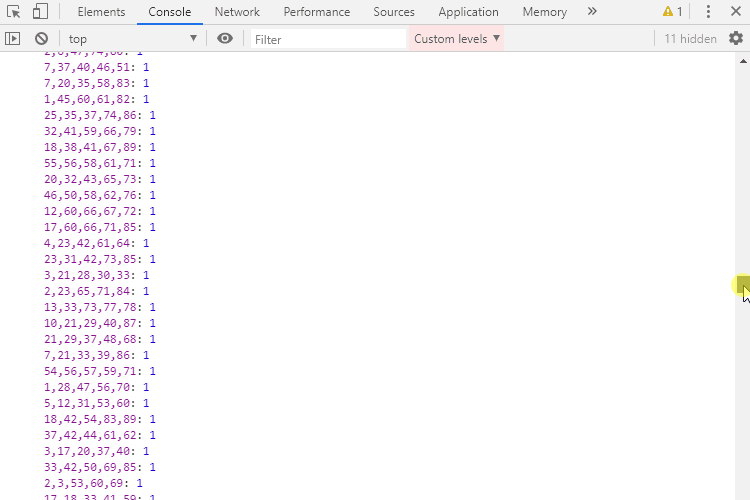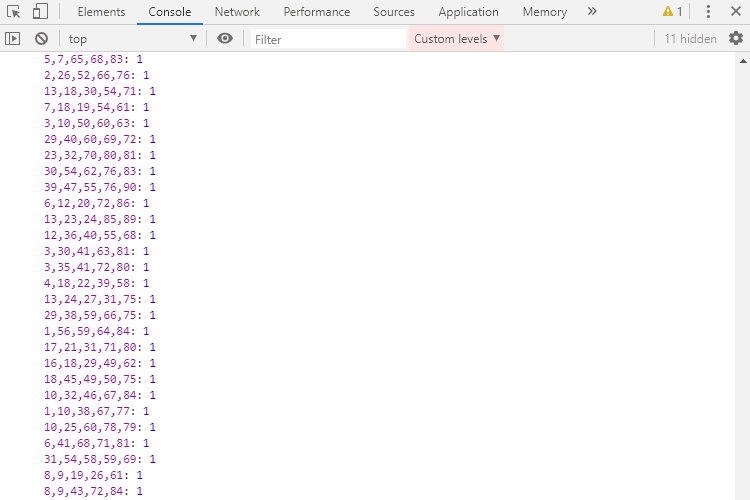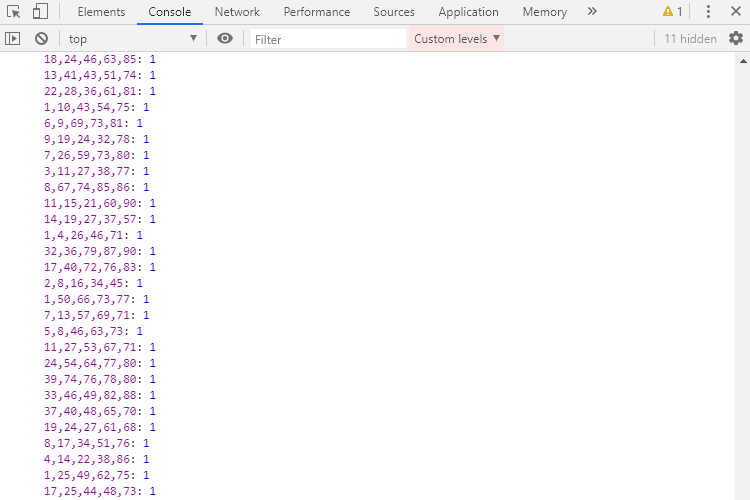
As you can see there’s not even a single set of winning numbers that have been drawn more than once during the span of 63 years. So what are the numbers that have been picked the most?
Again, we can create a new array containing all winning numbers and then count their occurrence:
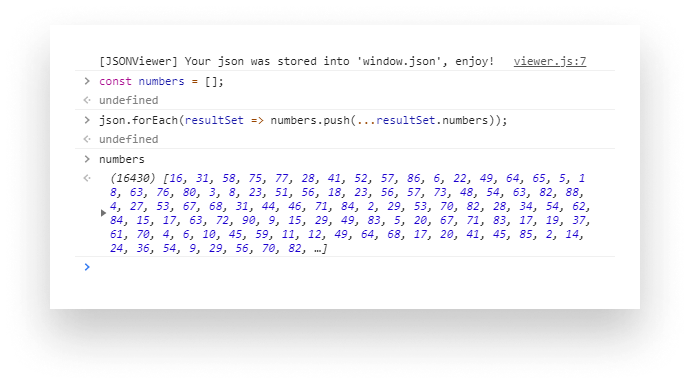
We can follow the same pattern as before, only this time we can use the spread operator to destruct the array of numbers into single values. Then using the same counting function with the combination of a simple sort algorithm, we can conclude that the most picked numbers are: 3, 1, 29, 75, and 15.
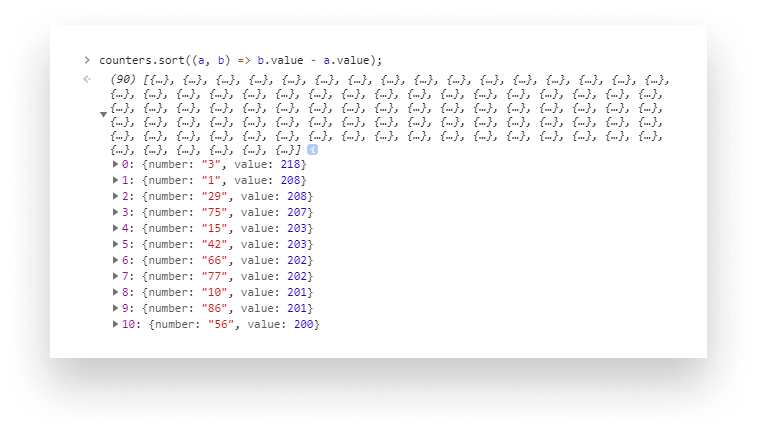
But if we scroll down to the least picked number, which is 88, even that has been picked 145 times.
So what are the odds of even winning the lottery? We know that we can choose between 90 different numbers and we have to do so 5 times. This gives us the following formula:
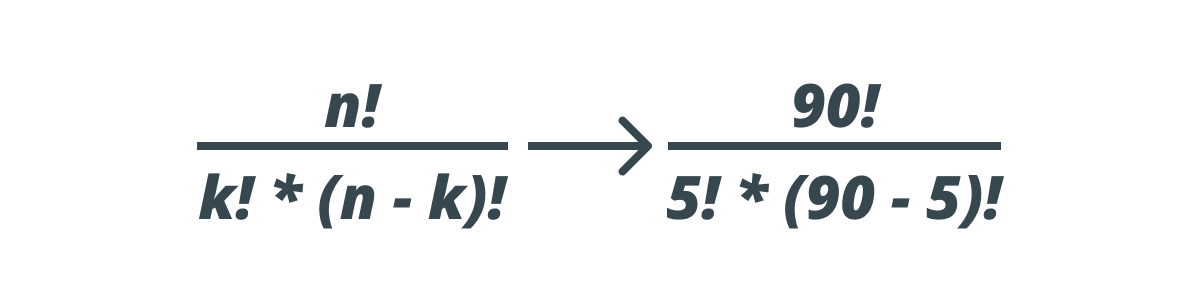
Where n is the number of alternatives we can pick and k is the number of choices we have. This leaves us with:
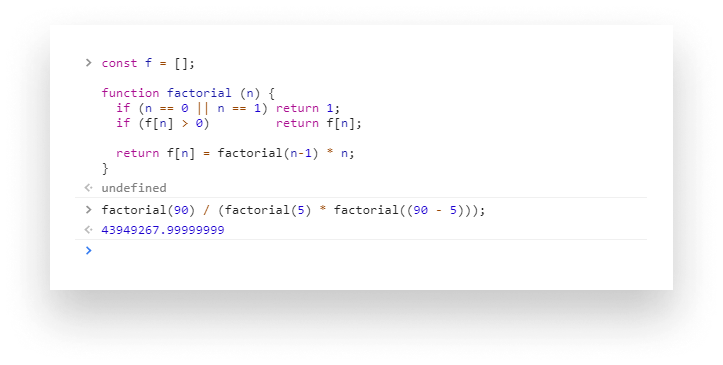
After creating a factorial function in the console we can calculate that we have roughly 1 in 43,949,268 chance to win this type of lottery with our choice of numbers which is probably just as random as our chance of winning.
Conclusion
So what’s the secret to winning the lottery? — There’s none. If there were any, people would be millionaires, and lottery companies would go bankrupt by tomorrow. You’re probably better off investing that money into yourself, your future, your family.
As we could see, Cypress makes it super easy to interact and gather information from web pages. Web scraping is all about interacting with the DOM and grabbing the necessary data so that we can work with it. With this technique, we can pretty much sniff data anywhere where an API is not available. And what are some other use-cases of web scraping?
For example, you can:
- Gather information from products to make comparisons
- Collecting training data for machine learning
- Pulling data from social media and forums for sentiment analysis
The list goes on, the sky is the limit.
Do you have any experience with web scraping? Have you got valuable tips and tricks when it comes to collecting data without an API? Let us know in the comments. Thank you for reading through! Happy coding. 👨💻


Rocket Launch Your Career
Speed up your learning progress with our mentorship program. Join as a mentee to unlock the full potential of Webtips and get a personalized learning experience by experts to master the following frontend technologies:
Courses



Recommended
How to Sync Your Client and Server After Being Offline
Introduction to Push Notifications
